Let’s create a speech service using the Azure portal, as follows.
Go to the Azure portal at https://portal.azure.com, search for speech service, and then create a new service.
As shown in the following screenshot, enter the project details such as your resource group speech service name and region details. Then, click on the Review + create button to create a speech service in an Azure environment.
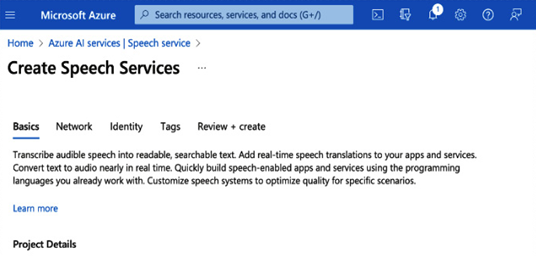
Figure 11.11 – Create Speech Services
Now, your Azure speech service is deployed, and you can go to that speech service resource by clicking on the Go to resource button on the deployment screen. Then, on the speech service resource screen, click on Go to speech studio. In Speech Studio, you can see various services for captioning with speech to text, post call transcription and analytics, and a live chat avatar, as shown in the following screenshot.
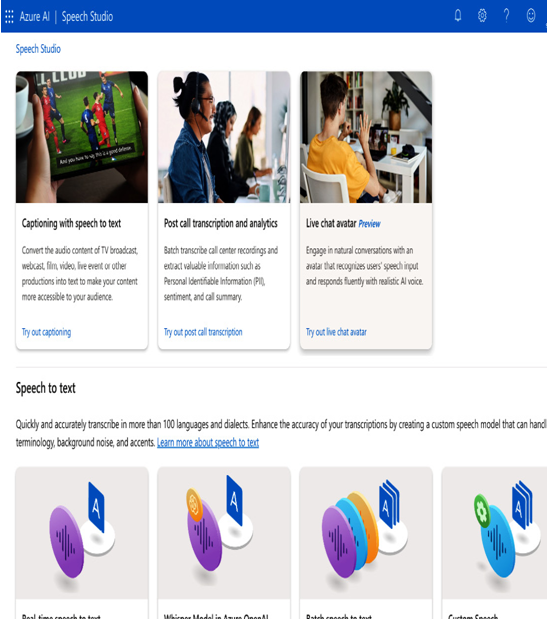
Figure 11.12 – Speech Studio
Speech to text
Now, let’s try to use the speech to text service. As shown in the following screenshot, you can drag and drop an audio file or upload it, and record audio with microphone. You can see the corresponding Text or JSON tabs on the right-side window for the uploaded audio file, as shown in the following screenshot.
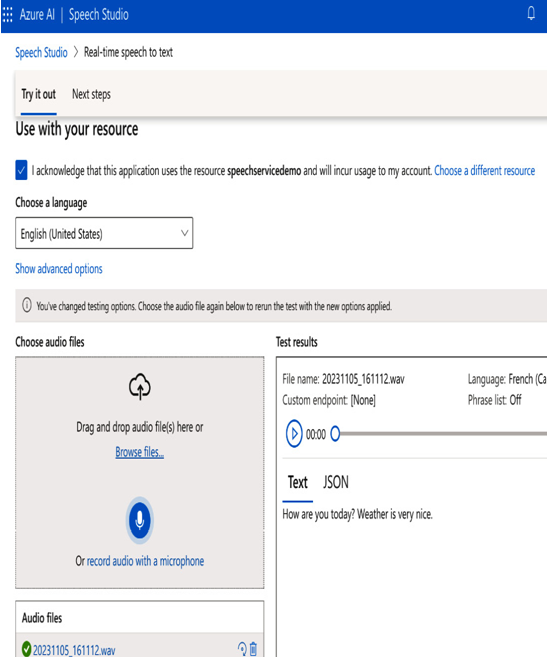
Figure 11.13 – Real-time speech to text
Speech translation
Now, let’s see how to translate the speech. On the following screen, we are translating from English to French. Let’s choose a spoken language and a target language.
Then, speak in English and record the audio with a microphone. The translated text in French is shown on the right side of the window, as shown in the following screenshot.
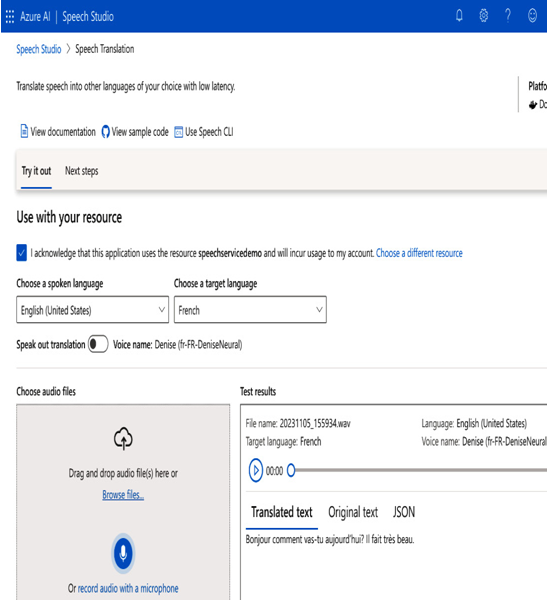
Figure 11.14 – Translated text test results
We can also see the original text on the Original text tab, as shown in the following screenshot:
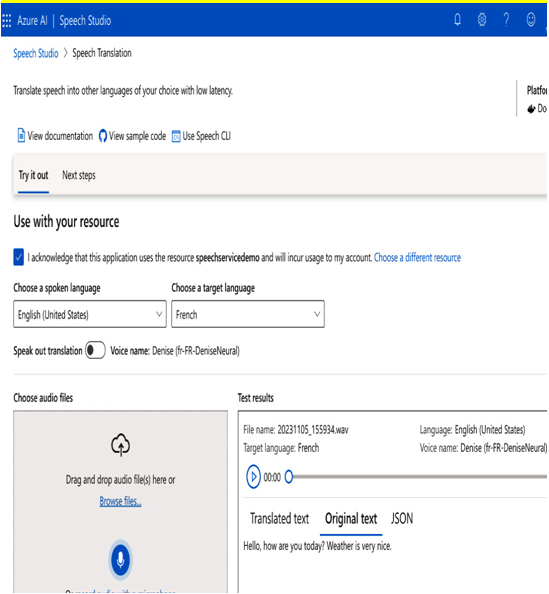
Figure 11.15 – Original text in test results
We have seen how to transcribe from speech to text and translate from English to French using Azure speech services. Aside from this, there are many other Azure speech services in Azure Speech Studio that you can apply, based on your requirements.
Summary
In this chapter, we explored three key sections that delve into the comprehensive process of handling audio data. The journey began with the upload of audio data, leveraging the Whisper model for transcription, and subsequently labeling the transcriptions using OpenAI. Following this, we ventured into the creation of spectrograms and employed CNNs to label these visual representations, unraveling the intricate details of sound through advanced neural network architectures. The chapter then delved into audio labeling with augmented data, thereby enhancing the dataset for improved model training. Finally, we saw the Azure Speech service for speech to text and speech translation. This multifaceted approach equips you with a holistic understanding of audio data processing, from transcription to visual representation analysis and augmented labeling, fostering a comprehensive skill set in audio data labeling techniques.
In the next and final chapter, we will explore different hands-on tools for data labeling.